Flowers Laboratory
FLOWing Epigenetic Robots and Systems
Human-Robot Interfaces for Learning Visual Objects
 While robots start to move from the constrained world of factories and enter the wildness of our living-rooms, onecentral question emerges: how personal and social robots can adapt themselves to unknown, unconstrained and constantly changing environment? Among the many interesting solutions one could imagine, we are interesting here in social learning where humans will guide the robot in the discovery of its surrounding. While social learning in robotics has been well studied from machine learning and perception point of view, we think that the role of the human-robot interaction and in particular of the interface and the human factors have been largely underestimated. We argue that in a real world application context where users are non necessarily experts in robotics and the robots have limited sensors, the interface play a key role for both making the interaction more robust but also to help humans be good teachers for their robots.
While robots start to move from the constrained world of factories and enter the wildness of our living-rooms, onecentral question emerges: how personal and social robots can adapt themselves to unknown, unconstrained and constantly changing environment? Among the many interesting solutions one could imagine, we are interesting here in social learning where humans will guide the robot in the discovery of its surrounding. While social learning in robotics has been well studied from machine learning and perception point of view, we think that the role of the human-robot interaction and in particular of the interface and the human factors have been largely underestimated. We argue that in a real world application context where users are non necessarily experts in robotics and the robots have limited sensors, the interface play a key role for both making the interaction more robust but also to help humans be good teachers for their robots.

We have applied this approach to a well-known and crucial social learning problem: teaching new visual objects to a robot. More precisely, we want to give the ability to the users to draw the robot’s attention, show a particular visual object and associate a name to this object so the robot can recognise it later on. This looks like a classical and well-studied visual object recognition problem, where you use a large collection of learning examples to train a classification system. But in a real world scenario, users would have to first create those database and collect learning examples of objects they want to teach. Then from the HRI point of view, this problem becomes how to push non-expert users to collect good learning examples through few and intuitive interactions?
Directly transposing human-like interaction, such as pointing or gaze following, to human-robot interaction seems tempting. Indeed, no specific training would be required, from a really young age humans already know how to draw’s attention and show objects to each other. Yet, while those interactions seem really naturals, they are in fact really dependent of our perceptual apparatus (size, position of the eye, field of view…). They are suffering from a lack of robustness when used with typical social robots, which in spite of their humanoids appearance have really different perceptual capacities. As illustrated by the video below, those “natural” human-like interactions become quite unintuitive when directly transposed to human-robot interaction:
Another approach would be to wave objects in front of the robot. This solves the attention problem but unfortunately this technique is limited to a specific kind of objects: the small and light ones. Furthermore, it is restrictive for elderly or disabled people, usually targeted by personal robotics applications.
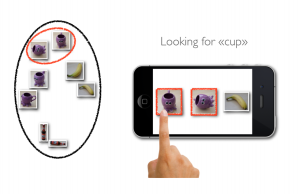
We have thus developed interfaces based on small mediator objects such as an iPhone, a Wiimote or a laser pointer. They were designed to facilitate joint attention situation. We make them light, easily transportable and easy to use. We also try to take advantage of already well known objects to facilitate their adoption by a large audience. As shown on the video, one of the key aspect of those interfaces is the use of “lasso” gestures where humans can directly encircle the object they want to show the robot (with the laser pointer or on the iPhone’s video feedback). This circling gesture has two very important properties, first it is a really intuitive way to show an object (used in other contexts than HRI) but also provides a rough yet useful segmentation of the object.

We have designed user’s studies to evaluate and compare our mediator based interfaces with a more direct transposition of human-like gestures. We were investigating how the interfaces impact both the user’s experience and the efficiency: i.e. the quality of the collected learning examples. Those user’s studies were designed as a robotic game. Indeed, we wanted to reproduce a realistic possible applications outside of the lab and games are a great way to motivate and implicate participants. Cut-scene videos and briefings are also powerful tools to efficiently provide the exact same instructions to a large number of participants (here more than 100 people).
Our results show that the interface has indeed a really strong impact on the quality of the learning examples. We have notably shown that without providing visual feedback of what the robot is perceiving on about a third of the collected examples the object is not visible at all! Thanks to a bag of visual words technique we have also compare the quality of the examples on a real recognition task. We could thus show that a specifically designed interface as the iPhone one naturally push non-expert users to provide learning examples as good as those collected by an expert user. More details about the methodology and the results are given in the references below. We have also shown that users find the mediator interfaces easier to use and more intuitive than the direct transposition of the human-like interaction!
This work has been extended to the use of acoustic words where a spoken word was associated to the visual representation of the object. This raises the problem of double clustering (in the acoustic and visual representation) without any invariant. We showed how the interface could be used to transparently ask the user to help to incrementally cluster the objects.
References
Teaching a robot how to recognize new visual objects: a study of the impact of interfaces
Pierre Rouanet, Pierre-Yves Oudeyer, Fabien Danieau and David Filliat
IEEE Transactions on Robotics, vol.29, no.2, pp.525,541, April 2013 Bibtex
A robotic game to evaluate interfaces used to show and teach visual objects to a robot in real world condition
Pierre Rouanet, Fabien Danieau and Pierre-Yves Oudeyer
6th ACM/IEEE International Conference on Human-Robot Interaction (HRI), 2011, Pages 313-320 Bibtex
An integrated system for teaching new visually grounded words to a robot for non-expert users using a mobile device
Pierre Rouanet, Pierre-Yves Oudeyer and David Filliat
The 9th IEEE-RAS International Conference on Humanoid Robot, Paris : France (2009) Bibtex
Apprendre à un robot à reconnaître des objets visuels nouveaux et à les associer à des mots nouveaux : le rôle de l’interface
Pierre Rouanet
Université Sciences et Technologies – Bordeaux I (04/04/2012), Pierre-Yves Oudeyer (Dir.) Bibtex
Address in Bordeaux

Inria Bordeaux Sud-Ouest
200, avenue de la vieille tour
33405, Talence
France
Address in Paris

U2IS
ENSTA ParisTech
828, bd des Maréchaux
91762 PALAISEAU CEDEX
France
Institutions
