| Human-Robot Collaboration | Exploration and Development in
Autonomous Systems |
Intelligent Tutoring Systems and
Education Software |
Perception and Control |
Robot
Design |
Control & Behavior Learning
Learning Grasping points
One of the basic skills for a robot autonomous grasping is to select
the appropriate grasping point for an object. Several recent works have
shown that it is possible to learn grasping points from different types
of features extracted from a single image or from more complex 3D
reconstructions. In the context of learning through experience, this is
very convenient, since it does not require a full reconstruction of the
object and implicitly incorporates kinematic constraints as the hand
morphology. These learning strategies usually require a large set of
labeled examples which can be expensive to obtain. In this paper, we
address the problem of actively learning good grasping points to reduce
the number of examples needed by the robot. The proposed algorithm
computes the probability of successfully grasping an object at a given
location represented by a feature vector. By autonomously exploring
different feature values on different objects, the systems learn where
to grasp each of the objects. The algorithm combines betabinomial
distributions and a non-parametric kernel approach to provide the full
distribution for the probability of grasping. This information allows
to perform an active exploration that efficiently learns good grasping
points even among different objects. We tested our algorithm using a
real humanoid robot that acquired the examples by experimenting
directly on the objects and, therefore, it deals better with complex
(anthropomorphic) handobject interactions whose results are difficult
to model, or predict. The results show a smooth generalization even in
the presence of very few data as is often the case in learning through
experience.
Active learning of visual descriptors for grasping using non-parametric smoothed beta distributions, Luis Montesano and Manuel Lopes. Robotics and Autonomous Systems, Accepted available online: 26-AUG-2011, 10.1016/j.robot.2011.07.013.
Learning grasping affordances from local visual descriptors,Luis
Montesano and Manuel Lopes. IEEE - International Conference on
Development and Learning (ICDL), Shanghai, China, 2009.

Policy-Gradient Methods
We propose a new algorithm, fitted natural actor-critic (FNAC) to allow for general function approximation and data reuse. We combine the natural actor-critic architecture with a variant of fitted value iteration using importance sampling. The method thus obtained combines the appealing features of both approaches while overcoming their main weaknesses: the use of a gradient-based actor readily overcomes the difficulties found in regression methods with policy optimization in continuous action-spaces; in turn, the use of a regression-based critic allows for efficient use of data and avoids convergence problems that TD-based critics often exhibit. We establish the convergence of our algorithm and illustrate its application in a simple continuous space, continuous action problem.
This algorithm can be used in different settings.
Learn to grasp by carefully coordinating all degrees of freedom of the hand (video) |
 Improve walking gait by
changing the parameters of the cycle generators that controls
the walking pattern. See video of the learning
progression and the robot walking around using the optimized
parameters (video). Improve walking gait by
changing the parameters of the cycle generators that controls
the walking pattern. See video of the learning
progression and the robot walking around using the optimized
parameters (video). |

Task Sequencing in Visual
Servoing
This experiment shows Baltazar performing a 6 dof sequence of tasks.
internal view (video) and
external view (video).
Also the same experiment but with an industrial robot:internal view (video) and external
view (video).

Relevant publications: Mansard et al. IROS06 (pdf)
Visual Servoing
This experiment shows Baltazar movement randonmly the arm in order to
estimate de visual Jacobian (video).
With this Jacobian Baltazar is able to do 2D visual servoing. In (video) we can see the features extracted
(2 points position and orientation) and the desired trajectory (hexagon
and triangle). In (video) we can see
the same movement from the other eye.
Relevant publications: Mansard et al. IROS06 (pdf)

Object Grasping
This experiment shows the capability of Grasping (video). The algorithm is based on 2 steps: the first is open-loop and uses a head-arm map moving the hand near to the object (initial position), the second step is a new algorithm that estimates online the image Jacobian and makes the final movement with visual servoing. The hand is controlled to close but because of the mechanical compliance the fingers adapt to the object.
Egosphere
This work presents a multimodal bottom-up attention system for the
humanoid robot iCub where the robot’s decisions to move eyes and
neck are based on visual and acoustic saliency maps.We introduce a
modular and distributed software architecture which is capable of
fusing visual and acoustic saliency maps into one egocentric frame of
reference.
This system endows the iCub with an emergent exploratory behavior
reacting to combined visual and auditory saliency.
The developed software modules provide a flexible foundation for the
open iCub platform and for further experiments and developments,
including higher levels of attention and representation of the
peripersonal space.

Multimodal Saliency-Based Bottom-Up Attention: A Framework for the Humanoid Robot iCub. . IEEE - International Conference on Robotics and Automation (ICRA'08), Pasadena, California, USA, 2008
Sound Localization
Being able to locate the origin of a sound is important for our
capability to interact with the environment. Humans can locate a sound
source in both the horizontal and vertical plane with only two ears,
using the head related transfer function HRTF, or more specifically
features like interaural time difference ITD, interaural level
difference ILD, and notches in the frequency spectra. In robotics
notches have been left out since they are considered complex and
difficult to use. As they are the main cue for humans’ ability to
estimate the elevation of the sound source this have to be compensated
by adding more microphones or very large and asymmetric ears. In this
paper, we present a novel method to extract the notches that makes it
possible to accurately estimate the location of a sound source in both
the horizontal and vertical plane using only two microphones and
human-like ears. We suggest the use of simple spiral-shaped ears that
has similar properties to the human ears and make it easy to calculate
the position of the notches. Finally we show how the robot can learn
its HRTF and build audiomotor maps using supervised learning and how it
automatically can update its map using vision and compensate for
changes in the HRTF due to changes to the ears or the environment.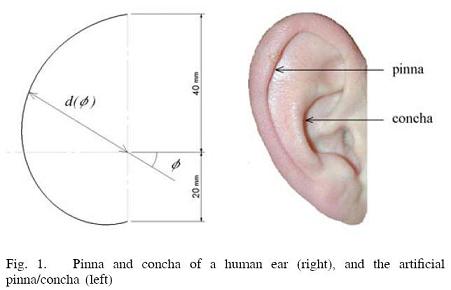

These videos show iCub localizing the source of sounds, in an anecoic chamber (video 1) and in an office room (video 2).
Sound localization for humanoid robots - building audio-motor maps based on the HRTF. . IEEE – Intelligent Robotic Systems (IROS'06), 2006.