Flowers AI & CogSci Lab
Artificial intelligence, Cognitive Sciences, Education and Scientific Discovery
Autonomous perceptual and representation learning
We address both fundamental problems such as autonomously discovering concepts or sensory-motor invariants and practical applications in autonomous or interactive scenarios, such as learning to recognize objects or affordances. The overall goal of our work is therefore to bridge the gap between very fundamental approaches and practical applications. We focus in particular on the role of actions in the formation of concepts such as objects and on exploiting multi-modality (audio-visual, visuo-motor and audio-motor) in concept discovery.
Incremental learning of visual objects
Incremental learning of visual objects

For example, during the MACSi project , we developed an approach that make it possible to learn incrementally new objects presented to the robot. This approach is applied on an iCub robot and is based on an initial segmentation of the scene into proto-objects based on coherent motion and depth. These proto-objects appearance is represented following the Bag of Visual Words approach using several complementary features to maximize the completeness of the encoded information (texture, color and their co-occurrences) and building the visual dictionaries on-line. Multi-view object models are then constructed by associating recognized views and views tracked during manipulations of an object. The key interest of this approach is to be able to learn object model during physical and social interaction without any image database and very limited prior knowledge, in particular it is able to segment objects from human or robot hands during manipulation.
We also worked on discrimination of categories suchs as self/body, objects and humans using the correlations between motor commands and visual information. Learning these categories make it possible to improve object models by making the robot manipulate these objets.
More details can be found in David Filliat and Natalia Lyubova publications.
Learning of motion and behavioral primitives
Learning motion primitives from simultaneous demonstrations
We are thus interested in studying representations and algorithms enabling to learn to recognize and/or reproduce such complex behaviors in a way that captures their combinatorial structure, which means learn the parts from combined demonstrations. We are more specifically interested in primitive motions that are combined together at the same time. We denote this kind of combinations as parallel combinations; a dancer executing a choreography provides a prototypical example of such a combination. Indeed a choreography might be formed by executing some particular step, a gesture with the left arm while maintaining some posture of the head and the right arm at the same time.

We study the use of machine learning techniques such as nonnegative matrix factorization to achieve motion decomposition from ambiguous demonstration. More information is available in our paper:
Mangin O., Oudeyer P.Y. (2012) Learning to recognize parallel combinations of human motion primitives with linguistic descriptions using non-negative matrix factorization, in IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura, Algarve (Portugal). [data][slides of presentation at IROS 2012] [video of presentation]
The data used in the paper is available online as the Choreography dataset (flowers.inria.fr/choreo/doc).
Decomposing behaviors in the feedback or reward space
Inverse feedback control and inverse reinforcement learning are techniques to infer a cost function that is optimized by an agent by only looking at the agent’s actions. We are interested in using these techniques to learn models of human behaviors based on intention. More typically challenges arise from the understanding of human behaviors from multiple tasks, and the use of clustering methods and dictionary learning techniques to discover lexicons of primitive intentions that explains observed behaviors.
Some work in that direction have been presented in our papers:
- Javier Almingol, Luis Montesano and Manuel Lopes, Learning Multiple Behaviors from Unlabeled Demonstrations in a Latent Controller Space. International Conference on Machine Learning (ICML), Atlanta, USA, 2013.
- Mangin O., Oudeyer P.Y. (2012) Learning the combinatorial structure of demonstrated behaviors with inverse feedback control, in Proceedings of 3rd International Workshop on Human Behavior Unterstanding (HBU 2012), pp. 134)147, Springer, LNCS 7559. (This article is about Factorial Inverse Feedback Learning). [slides]
Multimodal learning; language acquisition
Multimodal learning; language acquisition
A particular instance of multimodal learning is the learning of language where the learner has to relate perception of an object to the sound of its name. This problem is commonly referred to as the symbol grounding problem. For example, we shown how it is possible to learn the link between symbolic labels and gestures that compose choreographies.
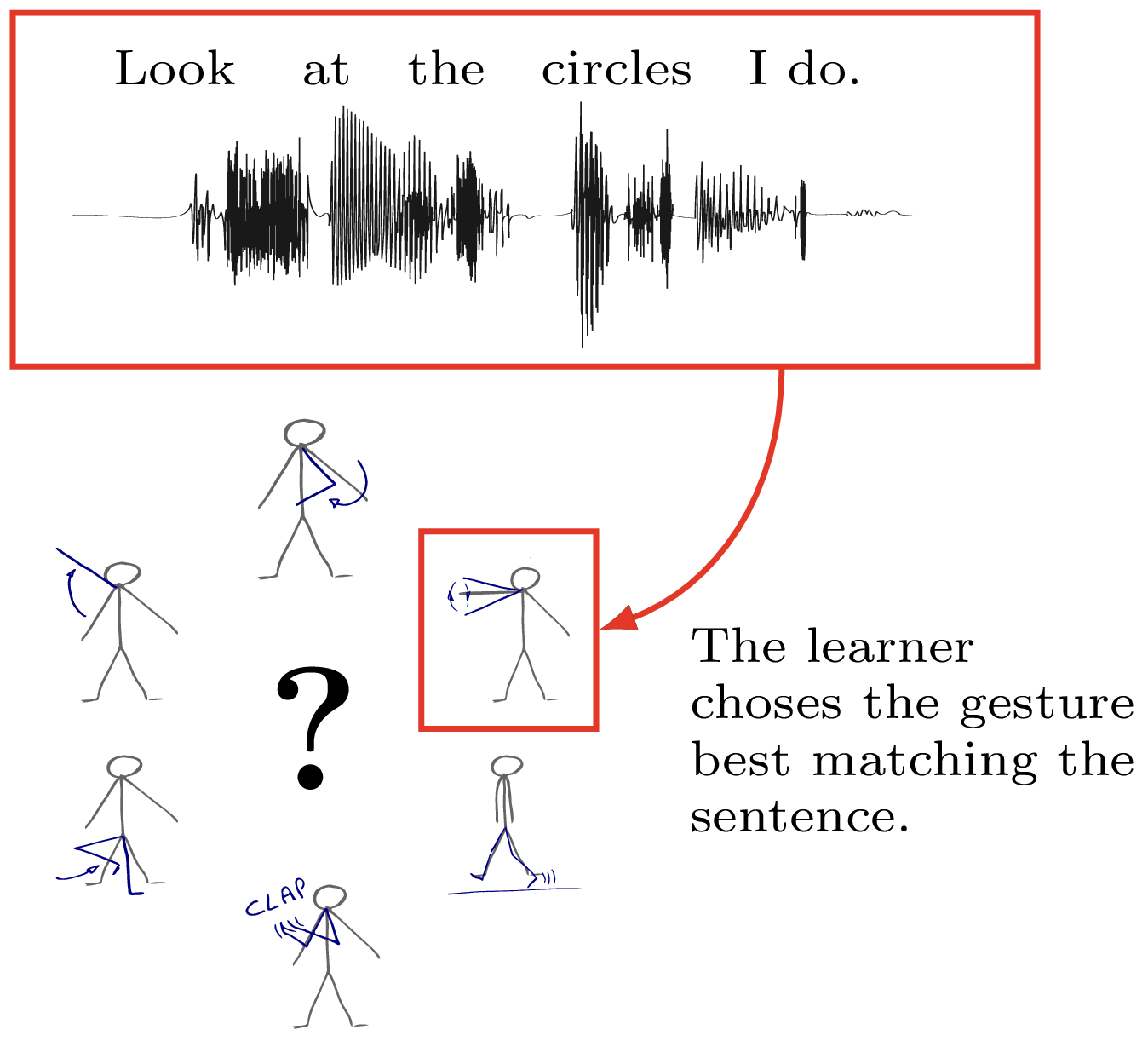
Outside the simpler case where one wants to learn concepts grounded in one modality and relate them to observed symbols (basic or structured classification), the interaction between the emergence of language symbols and classes of perceptual objects is actually more complex. For instance, while words often describe concepts that could directly emerge from perception and of interaction with the world, the learning of worlds to describe concepts often shapes the concepts themselves (as explained on this page). Learning the semantic concepts resulting from this interaction is thus better expressed in terms of learning directly from several sub-symbolic modalities.
The motion data used in the paper is available online as the Choreography 2 dataset. The code of the experiment is available on github.
More information on that subject can be found in our publication:
Mangin O., Oudeyer P.Y. (2013) Learning semantic components from sub-symbolic multi-modal perception. Proceedings of the third Joint IEEE International Conference on Development and Learning an on Epigenetic Robotics (ICDL-EpiRob 2013), Osaka (Japan). [pdf] [bibtex][code] [details]
Mangin O.The Emergence of Multimodal Concepts: From Perceptual Motion Primitives to Grounded Acoustic Words March 2014, Université de Bordeaux, France. [pdf] [bibtex] [defense video]
Inria Center of the University of Bordeaux

Inria Bordeaux Sud-Ouest
200, avenue de la vieille tour
33405, Talence
France
